入门: 神经网络(Neural Network)及 Python 实现

为了更好的理解深度学习,我决定从零开始构建一个神经网络(Neural Network)。
什么是神经网络? #
起源:M-P 模型(单层神经元) #
所谓M-P模型,其实是按照生物神经元的结构和工作原理构造出来的一个抽象和简化了的模型。简单点说,它是对一个生物神经元的建模。它实际上是两位科学家的名字的合称,1943年心理学家W.McCulloch和数学家W.Pitts合作提出了这个模型,所以取了他们两个人的名字(McCulloch-Pitts)。
先来看看神经元的简化示意图:
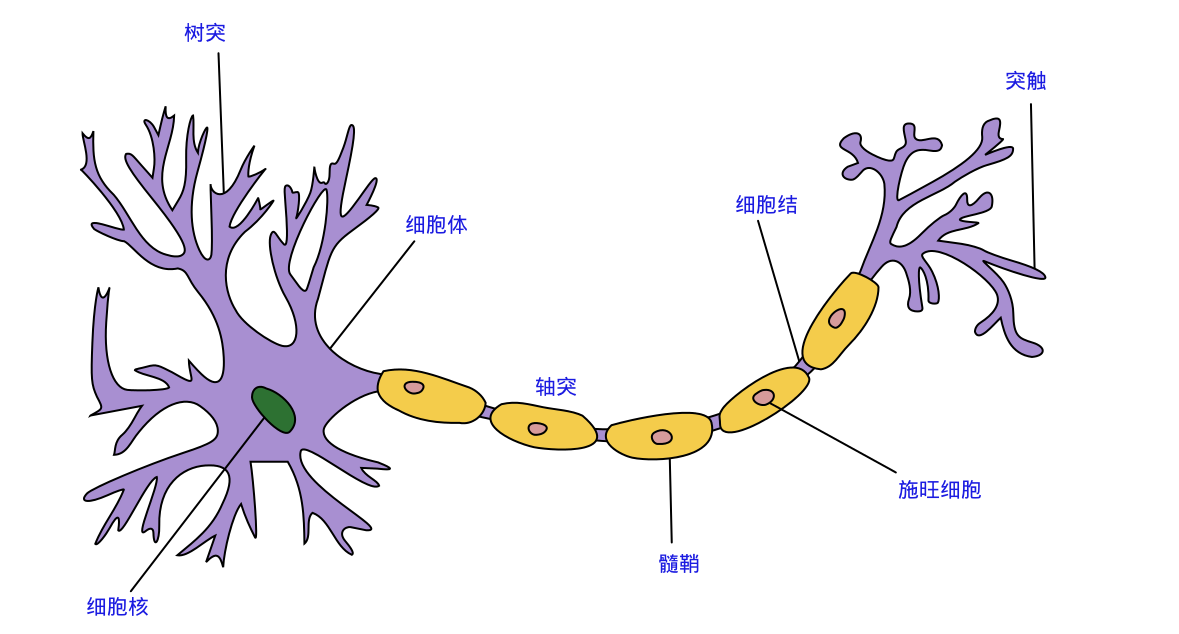
神经元在结构上由细胞体、树突(输入)、轴突(输出)和突触4部分组成。
- 每个神经元都是一个多输入单输出(轴突)的信息处理单元;
- 神经元输入(树突)分兴奋性输入和抑制性输入两种类型;
- 神经元具有空间整合特性和阈值特性(兴奋和抑制,超过阈值为兴奋,低于是抑制);
- 神经元输入与输出间有固定的时滞,主要取决于突触延搁;
我们可以把一个神经元想象成一个水桶,这个水桶侧边接着很多条水管(神经末梢),水管既可以将桶里的水输出去(抑制性),也可以将其他水桶的水输进来(兴奋性)。当桶里的水达到一个高度时,就会通过另一条管子(轴突)将水输送出去。由于水管的粗细不同,对桶里的水的影响程度(权重)也不同。水管对水桶里的水位的改变(膜电位)自然就是这些水管输水量的累加。当然,这样来理解并不是很完美,因为神经元中的信号是采用一个个脉冲串的离散形式,而这里的水则是连续的。
关于权值的理解,还有人做出一个非常形象的比喻。比如现在我们要选一个餐厅吃饭,于是对于某一个餐厅,我们有好几种选择因素 e.g.口味、位置、装潢、价格等等,这些选择因素就是输入,而每一个因素占的比重往往不同,比如我们往往会把口味和价格放在更重要的位置,装潢和位置则稍微不那么重要。很多个候选餐厅的选择结果最终汇总之后,就可以得到最后的决策。
按照生物神经元,我们建立M-P模型。下图,展示的就是 M-P 模型的示意图:
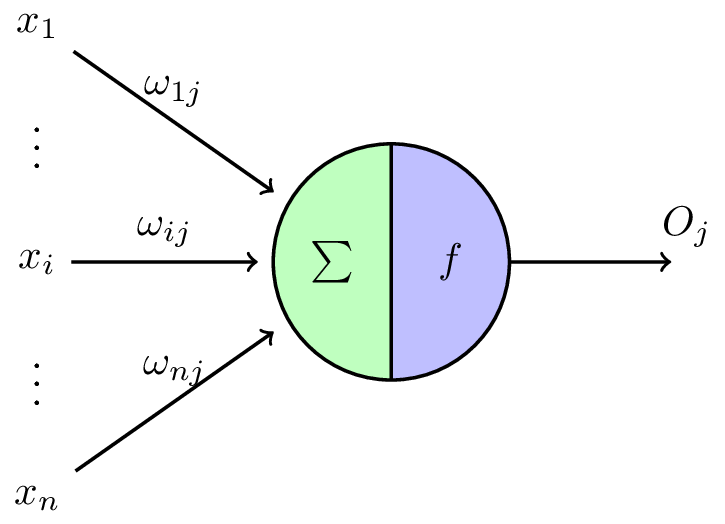
那么接下来就好类比理解了。我们将这个模型和生物神经元的特性列表来比较:

结合M-P模型示意图来看,对于某一个神经元j,它可能接受同时接受了许多个输入信号,用χi表示。
由于生物神经元具有不同的突触性质和突触强度,所以对神经元的影响不同,我们用权值 $w_{ij}$ 来表示,其大小则代表了突出的不同连接强度。
$T_j$ 表示为一个阈值,或称为偏置,超过阈值为兴奋,低于是抑制。
由于累加性,我们对全部输入信号进行累加整合,相当于生物神经元中的膜电位(水的变化总量),其值就为:
$$ net\_j’(t) = \sum_{i=1}^{n}{w_{ij}X_i(t)} - T_j $$
MLP:多层感知机(Multilayer Perceptron, 我们常说的神经网络 ) #
简单地将神经网络描述为将给定输入映射到所需输出的数学函数更容易理解一下。
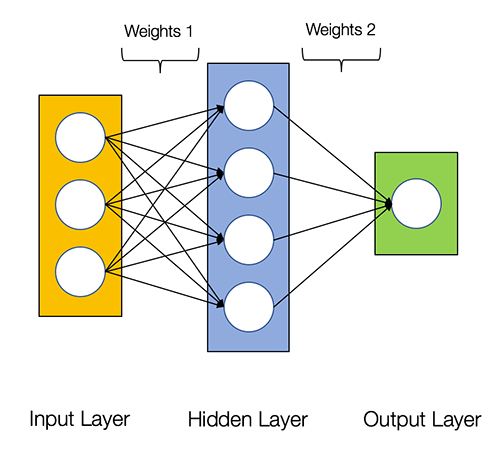
神经网络包含下面几个组件:
- 一个输入层(input layer): x
- 一个任意数量的隐藏层(hidden layers)
- 一个输出层(output layer): $ \hat{y} $
- 每一个层之间有一个权重(weight)集和偏置(bias)集: W 和 b
- 需要为每一个隐藏层选择一个激活函数(activation function), $\sigma$。这里,我们都是用 Sigmod 作为激活函数。
下面显示2层神经网络的架构(注意:当计算层数的时候,一般都会把输入层忽略掉)。
开始构建 #
使用 Python 创建一个神经网络的类:
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(y.shape)
神经网络的训练 #
一个 2-layer 神经网络的输出 $\hat{y}$ 是:
$$ \hat{y} = \sigma(W_2\sigma(W_1x+b_1)+b_2) $$
你可能注意到上一一个等式,权重 W 和偏置 b 是影响 $\hat{y}$。
很自然,右边值的权重和偏置决定预测的强弱。使用输入数据对权重和偏置的微调过程,就是我们所说的神经网络的训练。
训练过程的每一次迭代包含下面的步骤:
- 计算预测输出 $\hat{y}$ ,称之为前馈(feedforward)
- 更新权重和偏置,称之为反向反馈(backpropagation)
下面的序列图说明了该过程:

前馈(feedforward) #
正如我们所看到的,前馈就是简单的计算,现在看看代码时间
class NeuralNetwork:
...
def feedforward(self):
"""前馈"""
self.layer1 = sigmoid(np.dot(self.input, self.weights1))
self.output = sigmoid(np.dot(self.layer1, self.weights2))
然而,我们还需要一种评估预测好坏的方式。损失函数(Loss Function)就是这个用途。
损失函数(Loss Function) #
损失函数有很多种,选择应该由我们问题的性质决定。在这里,我们将 SSE(sum of sqares error,和方差)作为损失函数:
$$ SSE = \sum_{i=1}^n{(y - \hat{y})^2} $$ SSE 就是预测值和实际值的差异的和。差异是平方的,所以我们可以使用差的绝对值来衡量。
我们训练的目标实际找出最佳权重和偏置组合使得损失函数最小化。
反向反馈(Backpropagation) #
现在,我们已经测出了预测的误差(损失),我们需要寻找一种方式将误差反馈回去,来更新我们的权重和偏置。
为了知道调整权重和偏置的适当数量,我们需要知道损失函数相对于权重和偏置的导数(derivative)。
回想一下微积分函数的导数就是函数的斜率。
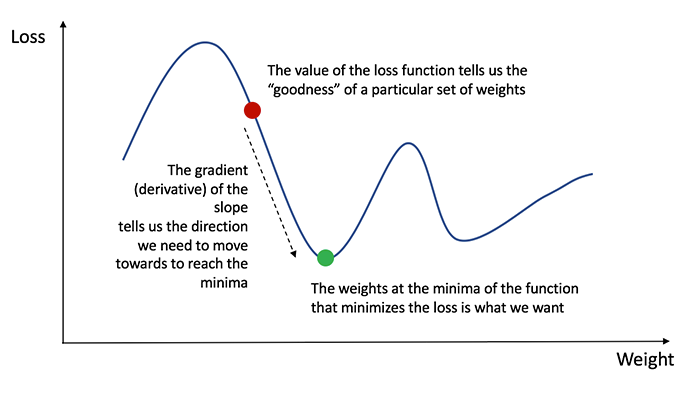
如果我们有导数,我们就能通过加减它来更新权重和偏置。这就是所谓的梯度下降。
然而,我们不能直接计算损失函数的导数,因为损失函数不包含权重和偏置。因此,我们需要链规则(chain rule)来帮助我们计算它
$$ Loss(y, \hat{y}) = \sum_{i=1}^{n}{(y-\hat{y})^2} $$
对 W 进行求导:
$$ \begin{split} \frac{\partial Loss(y, \hat{y})}{\partial W} &= \frac{\partial Loss(y, \hat{y}}{\partial \hat{y}} * \frac{\partial \hat{y}}{\partial z} * \frac{\partial z}{ \partial W} \\ &= 2(y-\hat{y}) * sigmoid 函数的导数 * x \\ &= 2(y-\hat{y}) * z(1-z) * x \end{split} $$
计算损失函数对权重的导数的推导。为了简化,我们只展示了一层神经网络的导数。
Phew!虽然很丑,但是这就是我们需要的——损失函数对权重的导数,来帮助我们调整我们的权重。
现在,我们把反向反馈函数添加到代码中:
class NeuralNetwork:
...
def backprop(self):
"""反向反馈"""
# 计算出各层的导数
d_weights2 = np.dot(self.layer1.T, (2*(self.y - self.output) * sigmoid_derivative(self.output)))
d_weights1 = np.dot(self.input.T, (np.dot(2*(self.y - self.output) * sigmoid_derivative(self.output), self.weights2.T) * sigmoid_derivative(self.layer1)))
# 使用导数来更新参数
self.weights1 += d_weights1
self.weights2 += d_weights2
整合在一起 #
现在,我们有了完整的神经网络的代码实现。让我们来应用到例子中,看看效果
| X1 | X2 | X3 | y |
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 0 |
我们的神经网络应该学习到立项的权重集来展示这个函数。请注意,仅仅通过检查来计算权重对我们来说并不是微不足道的。
让我们迭代 1500 次,看看会是什么结果。看看每一次迭代的损失,我们可以明显的看出损失单调递减到一个最小值。这与我们之前讨论过的梯度下降算法一致。
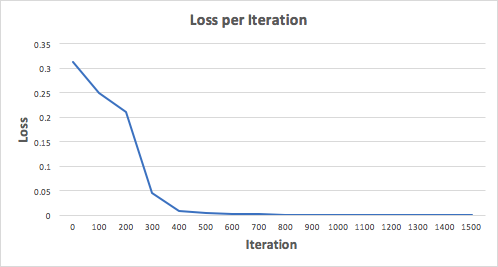
让我们看一下 1500 次迭代后神经网络最后的预测(输出):
| 预测 | Y(实际) |
|---|---|
| 0.023 | 0 |
| 0.979 | 1 |
| 0.975 | 1 |
| 0.025 | 0 |
我们做到了!我们前馈和反向反馈算法成功的训练了一个神经网络,他的预测收敛于真正的价值观。
注意到了预测值和实际值存在略微差别。这个是合理的,为了避免过拟合,让神经网络对未知数据有更好的泛化能力。
接下来呢? #
后续,我们将会深入讲解激活函数,学习率等等,如果有时间的话^_^。
最后的思考 #
我是从0开始学习,甚至我还用不用的语言构造自己的神经网络,过程是很有趣的。
虽然像 TensorFlow 和 Keras 这样的深度学习库,让我们不需要对神经网络内部机制有足够的了解,也能构建深度网络,但是能够更深入的了解,对后续的研究更有益。