理解特征工程 - 连续型数值特征

介绍 #
Money makes the world go round(金钱驱动整个世界运转),无论你同不同意,有些时候你无法忽视它。在数字革命的时代,Data makes the world go round(数据驱动整个世界运转) 这句话更准确。事实上,无论数据的规模大小,数据已经成为企业、公司和组织的首要(first class)资产。一个智能系统,无论其复杂性,都需要强大的数据支撑。智能系统的核心,我拥有一个多个基于机器学习、深度学习或者统计方法的算法来消费数据,收集知识,并在一段时间内提供智能洞见(Insight)。算法本身很幼稚,不能适用于原始数据。因此,从原始数据中提取有意义的特征是非常重要的,特闷可以被算法理解并消费。
标准机器学习任务管道 #
任何一个智能系统基本上都包含一个点对点的管道,从摄取原始数据,利用数据处理技术来清洗(wrangle),处理和工程化从这些数据中提取有意义的特征和属性。然后,我们时常利用如统计模型或者机器学习模型来模型化这些特征,然后根据需要解决的问题,部署该模型。如下展示的是是基于 CRISP-DM 工业处理模型标准的机器学习管道
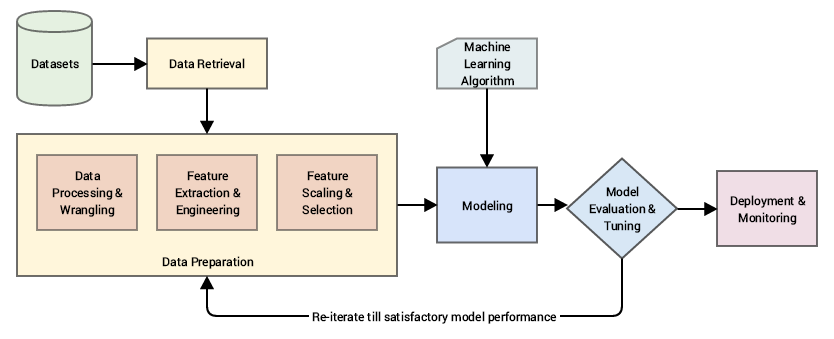
直接在原始数据之上建立模型是很蛮干的,因为我们不可能得到想要的结果和指标,算法也不会智能到自动从原始特征中提取有意义的特征(也存在一些自动特征提取技术,从深度学习方法论角度看,在一定程度上是可行的,但是更多应用在特征工程之后)。
我们主要关注的领域属于 数据准备(data preparation ) 方面,如上图所示,我们使用各种方法论,以便在经过必要的 清洗(wrangling) 和 预处理(pre-processing) 之后从原始数据中提取有意义的属性或特征。
动机 #
特征工程 是构建任何智能系统的重要组成部分。尽管你有很多更新的方法学,如 深度学习 和 元启发式(meta-heuristics) 有助于自动机器学习,但每个问题都是特定领域的,而更好的特性(适合问题)往往是系统性能的决定因素。特征工程 是一门艺术同样也是一门科学,这就是数据科学家在建模之前通常将 70% 的时间用于数据准备阶段的原因。 我们来看看几位来自数据科学领域知名人士的特征工程相关评价。
“Coming up with features is difficult, time-consuming, requires expert knowledge. ‘Applied machine learning’ is basically feature engineering.”
““解决特征问题是极其困难、耗时以及要求专业知识。应用机器学习(Applied machine learning) 基本上是特征工程。”
—— 吴恩达
他基本上强调了我们之前所提的 —— 数据科学家需要花接近 80% 的时间在特征工程上(很困难、耗时的过程,同时要求 **领域知识(Domain Knowledge)**和数学计算)。
“Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.”
“特征工程 是将 原始数据 转换成 特征 的处理过程,这些 特征 能更好讲 潜在问题 映射成 预测模型 ,提高 模型 在 看不见的数据 的预测精度”
—— Dr. Jason Brownlee
特征工程 就是将数据转换为特征的过程,作为机器学习模型的输入;高质量的特征有助于提高整体模型性能。特征非常依赖于潜在的问题。因此,尽管机器学习任务在不同场景下是相同的,像垃圾邮件分类器或者字迹识别,不同的场景下的特征提取将会是不同。
来自华盛顿大学的 Pedro Domingos 教授(《终极算法》的作者)的标题为 “A Few Useful Things to Know about Machine Learning” 的 Paper 中提到:
“At the end of the day, some machine learning projects succeed and some fail. What makes the difference? Easily the most important factor is the features used.”
“在最后,一些机器学习项目成功,而另一些失败了。什么导致他们之间的不同?最重要的因子是使用的特征”
— Prof. Pedro Domingos
让你对特征工程有所启发的最后引用来自著名的 Kaggler,Xavier Conort。你们大多数人已经知道,经常在Kaggle上发布艰难的现实世界中的机器学习问题,而这些问题通常对所有人开放。
“The algorithms we used are very standard for Kagglers. …We spent most of our efforts in feature engineering. … We were also very careful to discard features likely to expose us to the risk of over-fitting our model.”
“真的 Kaggler 使用的算法是非常标准的。……我们花了很大的努力在特征工程上……我们也很小心地丢弃容易造成模型过拟合的特征”
— Xavier Conort
理解特征 #
特征通常是在原始数据之上的特定表示,他是一个相对独立,可衡量的属性,通常由数据集的列来描述。考虑一个通用的二维数据集,每一个观察结果都由一行(Row)描述,每个特征由一列(Column)描述,这些列将具有特定的观测值。
正如上述例子的表格,每一个行指定一个特征向量,而所有观测值的特征向量构成一个 2 维特征矩阵,被称为特征集。这个类似于呈现2维数据的数据框(data frame)或者电子表格(Spreadsheets)。典型的机器学习算法可用于数值矩阵或者 张量(tensor),因此大部分特征工程技术都是将原始数据转化成一些数值形式以便容易被算法理解。
特征大体上可以分为两个大类:
- 原始特征:直接从数据集中获取,而不用额外的数据操作或工程。
- 派生特征(Derived feature):通常是通过特征工程获取,我们从已有的数据数据中提取出特征。
一个简单的例子就是从雇员数据集中包含生日的,通过和当前时间相减,创建出岁数的特征。
数据的类型和格式也是各种各样,包括结构化和非结构化的。在这篇文章中,我们将集中讨论处理处理结构化数值数据的特诊工程策略。
数值类型数据的特征工程 #
数字数据一般以标量(scalar)的形式描述观察,记录或者尺寸。这里,我们讲的数值类型数据就是**连续型数据(Continuous data)**而不是离散数据(它一般以分类形式来描述的)。数值型数据也可以被呈现为向量(Vector,向量中的每一个值或实体都表示一个特定的特征)。整型和浮点型是连续型数据最常见广泛使用的的数值类型。虽然数值可以直接喂给机器学习模型,但是你仍然在构建模型前,根据相关的场景、问题和领域进行特征工程。因此仍然有特征工程的需求。