Python - 简单的交互式数据分析

交互式 Python #
Python 是一个编程语言,它允许你快速创建和简单地编码就能完成相当复杂的任务。使用交互式 Python 解释器,试试输入一些命令来弄清楚它们工作原理。如果你完成一些基本 Python
教程,这里第一步对于你来说非常简单,只需要在命令行输入 python。
python 命令将会打开一个解释器,你可以在里面输入一些命令,并且实时返回结果给你。这是 powerful one-liners 的一个非常简单的例子:
$ python
Python 2.7.6 (default, Mar 22 2014, 22:59:56)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import pprint
>>> pprint.pprint(zip(('Byte', 'KByte', 'MByte', 'GByte', 'TByte'), (1 << 10*i for i in xrange(5))))
[('Byte', 1),
('KByte', 1024),
('MByte', 1048576),
('GByte', 1073741824),
('TByte', 1099511627776)]
>>>
虽然交互式环境很有用,但并不助于对 Python 的更深入的探索。在你的 python 之旅的早期,你可以听过 IPython。IPython 在 Python 的解释器的基础上,还提供了很多好用的特性,其中包括:
- tab 补齐
- 对象探测(exploration)
- 历史命令
打开 IPython 和打开 Python 一样简单,但是你马上就注意到很不同的交互界面:
$ ipython
Python 2.7.6 (default, Mar 22 2014, 22:59:56)
Type "copyright", "credits" or "license" for more information.
IPython 2.3.0 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]: import pprint
In [2]: pprint.pprint(zip(('Byte', 'KByte', 'MByte', 'GByte', 'TByte'), (1 << 10*i for i in xrange(5))))
[('Byte', 1),
('KByte', 1024),
('MByte', 1048576),
('GByte', 1073741824),
('TByte', 1099511627776)]
In [3]: help(pprint)
In [4]: pprint.
pprint.PrettyPrinter pprint.isrecursive pprint.pprint pprint.warnings
pprint.isreadable pprint.pformat pprint.saferepr
In [4]: pprint.
在这个例子中,我运行同样的命令,得到了相同的输出,可以尝试下 help 函数中,意识使用 TAB 键对 pprint 进行补齐。我还使用的另一个命令,使用向上的光标可以查看我输入的命令历史,编辑它们和执行结果:
In [4]: pprint.pprint(zip(('Byte', 'KiloByte', 'MegaByte', 'GigaByte', 'TeraByte'), (1 << 10*i for i in xrange(5))))
[('Byte', 1),
('KiloByte', 1024),
('MegaByte', 1048576),
('GigaByte', 1073741824),
('TeraByte', 1099511627776)]
In [5]: pprint.pprint(zip(('Byte', 'KByte', 'MByte', 'GByte', 'TByte'), (1 << 10*i for i in xrange(5))))
[('Byte', 1),
('KByte', 1024),
('MByte', 1048576),
('GByte', 1073741824),
('TByte', 1099511627776)]
IPython 获取对象的帮助也很方便。如果你遇到麻烦,尝试使用 ? 获取更多信息:
In [9]: s = {'1','2'}
In [10]: s?
Type: set
String form: set(['1', '2'])
Length: 2
Docstring:
set() -> new empty set object
set(iterable) -> new set object
Build an unordered collection of unique elements.
In [11]:
IPython 提供的这些功能很 cool 而且有用,所以我鼓励你在你的系统中安装它并使用它。
IPython Notebook #
IPython 非常有用;在 Django 项目,我已经使用很多年了。大概在 2011 年,Django 把 IPython notebook 引进到它的强大工具集中。由于某些原因,很迟才用上它;但是现在我已经改变了想法,使用它;我可以看到她所散发的无穷力量。
IPython Notebook, 简单地概括就是在浏览器中提供了 IPython 控制台。不过,它不仅仅是在浏览器中提供类 IPython 的特性,还提供了很易用的记录你的操作步骤和分享功能。在业务应用方面,有两个令人印象深刻的特点:
- Notebooks 易于交互和探索你的数据。
- 数据探索需要自记录(self-documenting)和分享功能。
想象你一下你正在使用 Excel,比如创建一个数据透视表(Pivot Table),或者做一些其他的分析。如果你想要向别人解释如何操作,你会怎么做呢?截图和注释?通过默写屏幕记录工具?还是直接把 Excel 文档给他们,让他们自己把它弄清楚?
上面都是很糟糕的建议;Excel 在 ad-hoc(即席) 分析领域的霸主地位导致了它成为了业界标准。当然,IPython Notebook 与 pandas 配合提供了一个分析大量数据和团队分享的有效途径。
Python 数据分析库 #
pandas, Python 的一个数据分析库,由 BSD 授权,提供高性能,易于使用的数据结构和数据分析工具。Pandas 是一个非常复杂的程序,你可以使用它做非常复杂数学计算。
启动环境 #
启动 ipython notebook 会话:
$ ipython notebook
你的浏览器会自动打开,并自动跳转到 notebook 的页面。这里主屏幕的截图(你有可能是空白的,这里只是展示一些例子):
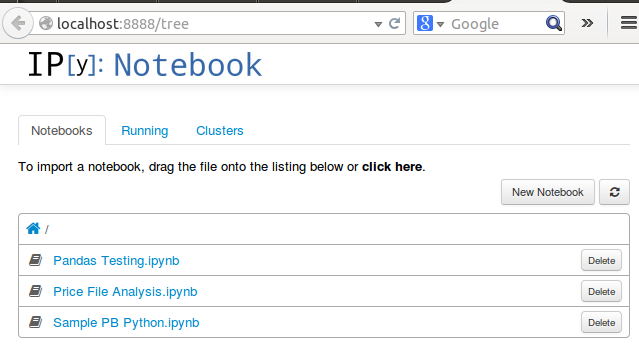
点击 New Notebook 按钮,启动新的环境开始编码:
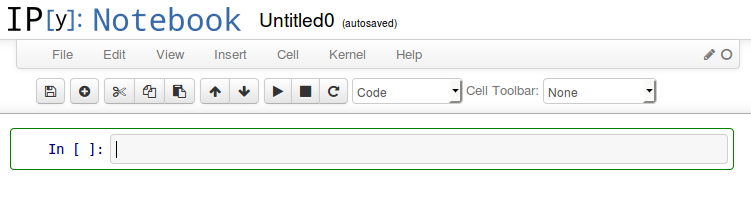
你将看到的输入框非常像之前我们看到的 IPython 命令提示符。
文章接下来的部分,我将讲解在输入框输入各种命令。我使用 reSt(reStructedText,一种标记语言)格式 下载全部的会话,因此,它能与我的博客无缝地整合在一起。
使用 Pandas 进行快速数据分析 #
现在,我使用我的 notebook 开始,我做一些更强大的分析。
首先,我们需要导入标准的 pandas 库
import pandas as pd
import numpy as np
接下来,我们读取样本数据:
SALES=pd.read_csv("sample-sales.csv")
SALES.head()
| Account Number | Account Name | sku | category | quantity | unit price | ext price | date | |
|---|---|---|---|---|---|---|---|---|
| 0 | 803666 | Fritsch-Glover | HX-24728 | Belt | 1 | 98.98 | 98.98 | 2014-09-28 11:56:02 |
| 1 | 64898 | O'Conner Inc | LK-02338 | Shirt | 9 | 34.80 | 313.20 | 2014-04-24 16:51:22 |
| 2 | 423621 | Beatty and Sons | ZC-07383 | Shirt | 12 | 60.24 | 722.88 | 2014-09-17 17:26:22 |
| 3 | 137865 | Gleason, Bogisich and Franecki | QS-76400 | Shirt | 5 | 15.25 | 76.25 | 2014-01-30 07:34:02 |
| 4 | 435433 | Morissette-Heathcote | RU-25060 | Shirt | 19 | 51.83 | 984.77 | 2014-08-24 06:18:12 |
现在我们使用数据透视表来汇总销量,把数据转换成有意义的信息。我们先从一些简单的开始:
report = SALES.pivot_table(values=['quantity'],index=['Account Name'],columns=['category'], aggfunc=np.sum)
report.head(n=10)
| quantity | |||
|---|---|---|---|
| category | Belt | Shirt | Shoes |
| Account Name | |||
| Abbott PLC | NaN | NaN | 19 |
| Abbott, Rogahn and Bednar | NaN | 18 | NaN |
| Abshire LLC | NaN | 18 | 2 |
| Altenwerth, Stokes and Paucek | NaN | 13 | NaN |
| Ankunding-McCullough | NaN | 2 | NaN |
| Armstrong, Champlin and Ratke | 7 | 36 | NaN |
| Armstrong, McKenzie and Greenholt | NaN | NaN | 4 |
| Armstrong-Williamson | 19 | NaN | NaN |
| Aufderhar and Sons | NaN | NaN | 2 |
| Aufderhar-O'Hara | NaN | NaN | 11 |
这个命令给我们展示每个用户购买的产品数量 —— 所有只要一个命令!看到它强大的同时,你将会注意到输出中有一堆的数据是 NaN。这个的意思是非数字(Not A Number),意思就是此处无值。
如果使用 0 代替,是不是看起来更美观清晰?这个就是 fill_value 的用途:
report = SALES.pivot_table(values=['quantity'],index=['Account Name'],columns=['category'], fill_value=0, aggfunc=np.sum)
report.head(n=10)
| quantity | |||
|---|---|---|---|
| category | Belt | Shirt | Shoes |
| Account Name | |||
| Abbott PLC | 0 | 0 | 19 |
| Abbott, Rogahn and Bednar | 0 | 18 | 0 |
| Abshire LLC | 0 | 18 | 2 |
| Altenwerth, Stokes and Paucek | 0 | 13 | 0 |
| Ankunding-McCullough | 0 | 2 | 0 |
| Armstrong, Champlin and Ratke | 7 | 36 | 0 |
| Armstrong, McKenzie and Greenholt | 0 | 0 | 4 |
| Armstrong-Williamson | 19 | 0 | 0 |
| Aufderhar and Sons | 0 | 0 | 2 |
| Aufderhar-O'Hara | 0 | 0 | 11 |
这样,它看起来干净多了!我们将在这个例子中演示数据透视表的更强大的地方。让我们算算他们的总销售收入:
report = SALES.pivot_table(values=['ext price','quantity'],index=['Account Name'],columns=['category'], fill_value=0,aggfunc=np.sum)
report.head(n=10)
| ext price | quantity | |||||
|---|---|---|---|---|---|---|
| category | Belt | Shirt | Shoes | Belt | Shirt | Shoes |
| Account Name | ||||||
| Abbott PLC | 0.00 | 0.00 | 755.44 | 0 | 0 | 19 |
| Abbott, Rogahn and Bednar | 0.00 | 615.60 | 0.00 | 0 | 18 | 0 |
| Abshire LLC | 0.00 | 720.18 | 90.34 | 0 | 18 | 2 |
| Altenwerth, Stokes and Paucek | 0.00 | 843.31 | 0.00 | 0 | 13 | 0 |
| Ankunding-McCullough | 0.00 | 132.30 | 0.00 | 0 | 2 | 0 |
| Armstrong, Champlin and Ratke | 587.30 | 786.73 | 0.00 | 7 | 36 | 0 |
| Armstrong, McKenzie and Greenholt | 0.00 | 0.00 | 125.04 | 0 | 0 | 4 |
| Armstrong-Williamson | 1495.87 | 0.00 | 0.00 | 19 | 0 | 0 |
| Aufderhar and Sons | 0.00 | 0.00 | 193.54 | 0 | 0 | 2 |
| Aufderhar-O'Hara | 0.00 | 0.00 | 669.57 | 0 | 0 | 11 |
如果我们想,你可以把结果导入到 Excel 中。我们要把它转换成 DataFrame,然后写到 Excel 文件中:
pd.DataFrame(report).to_excel('report.xlsx', sheet_name='Sheet1')
看一下我使用的 pandas 的版本,因为新的版本引入很多新的语法:
ln [15]: pd.__version__
0.14.1
最后的思考 #
这个文章的目的就是展示对交互式 python 工具的基本了解,和如何使用它做一些快速可以重现的复杂分析。